The failure no one expects
A payment service starts returning 503s to about 10% of requests. It’s not down — probably just briefly overloaded. A container is restarting. Nothing unusual.
Except that every client that receives a 503 error retries. That’s what they’re supposed to do.
The service now receives 10% more traffic than before.
Failure rate climbs to 20%.
More clients retry. Traffic climbs again.
Failure rate hits 40%, then 70%.
And within seconds, the service that was handling a minor hiccup becomes completely unreachable. Every dependent system starts timing out. Incident alerts go off across the board.
No component failed. No code was broken. Every client behaved exactly as designed.
And yet, the entire system is down.
This is the real danger with retries: the recovery mechanism becomes the failure.
To understand why, you need to look at what retries actually do to a system under stress.
What retries actually change
Retries exist because distributed systems are unreliable. Networks drop packets. Databases restart. Containers get rescheduled.
Most of these failures are transient. A single retry, half a second later, usually succeeds. That’s why retries feel like a free reliability win.
But retries aren’t free.
Every retry is a request you chose to duplicate.
When a system is healthy, duplicated requests are absorbed without notice. When a system is degraded, duplicated requests become the problem.
You’re not fighting the original failure anymore. You’re fighting the load you generated trying to recover from it.
And that changes the math. Retries don’t just recover failures. Under load, they amplify them.
Why this happens
Three forces turn retries against you.
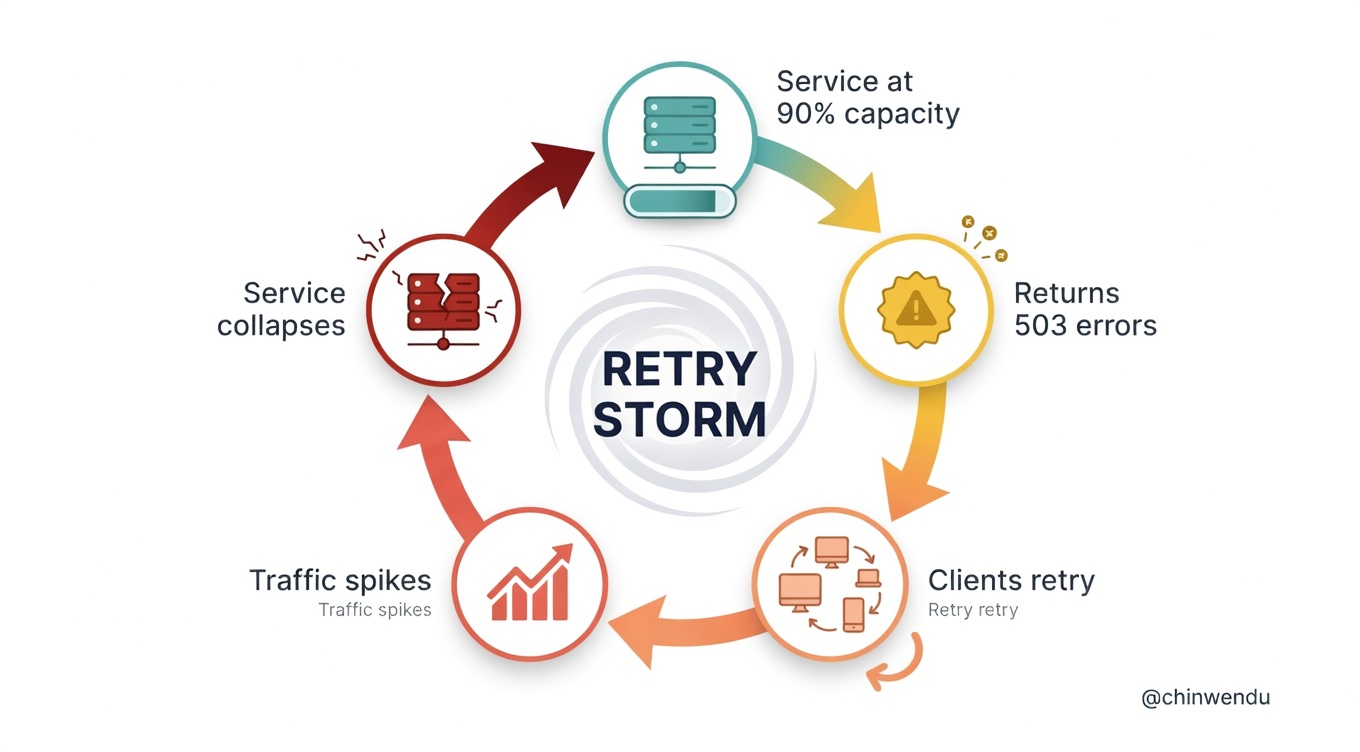
The first is the feedback loop. A struggling service returns errors. Errors trigger retries. Retries add load. Load causes more errors. Each cycle makes the next one worse. This is what SREs call a retry storm, and it can collapse a service in seconds.
The second is the thundering herd. When a dependency goes down and comes back up, every client that was accumulating retries fires them at once. The service that just recovered gets slammed with a wall of traffic and falls right back over. It’s a recovery pattern that prevents recovery.
The third is non-idempotent operations. If a payment request times out, did the charge go through? If you retry and the original actually succeeded, you’ve just double-charged the customer. Same thing with booking creations, wallet debits, notification sends, and similar operations. Without idempotency, retries corrupt data.
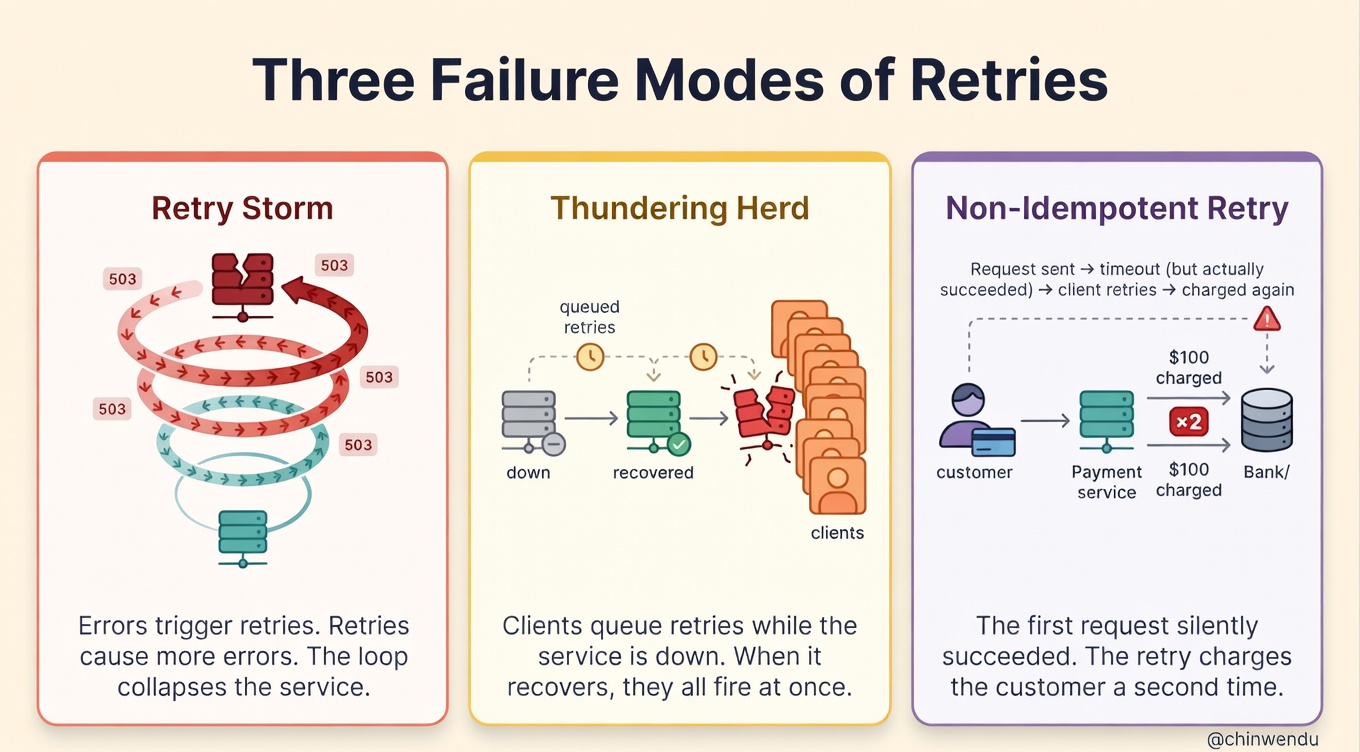
Each of these is a correctness failure dressed up as a reliability feature.
So the question becomes: how do you retry without causing the thing you’re trying to prevent?
The simplest fix most teams miss
You don’t need to eliminate retries. You need to control them.
Rule of thumb: a retry should cost the client more than the server.
If retries are free for the client, they’ll flood your service the moment anything goes wrong. If retries cost the client (in time, in budget, in circuit state), they self-regulate.
This is where backoff, jitter, and budgets come in.
Exponential backoff makes each retry wait longer than the last. For example, 100ms → 200ms → 400ms → 800ms. The client pays a time cost that grows with every attempt, giving the server room to recover.
Jitter adds randomness to that delay. Without it, thousands of clients retry at exactly the same intervals, creating synchronised waves of traffic. With it, the retries spread out naturally.
Retry budgets cap the number of retries the system as a whole is allowed to make. Instead of giving every request three retries, you say: retries cannot exceed 10% of total request volume. Once you hit the cap, new requests fail fast instead of piling on.
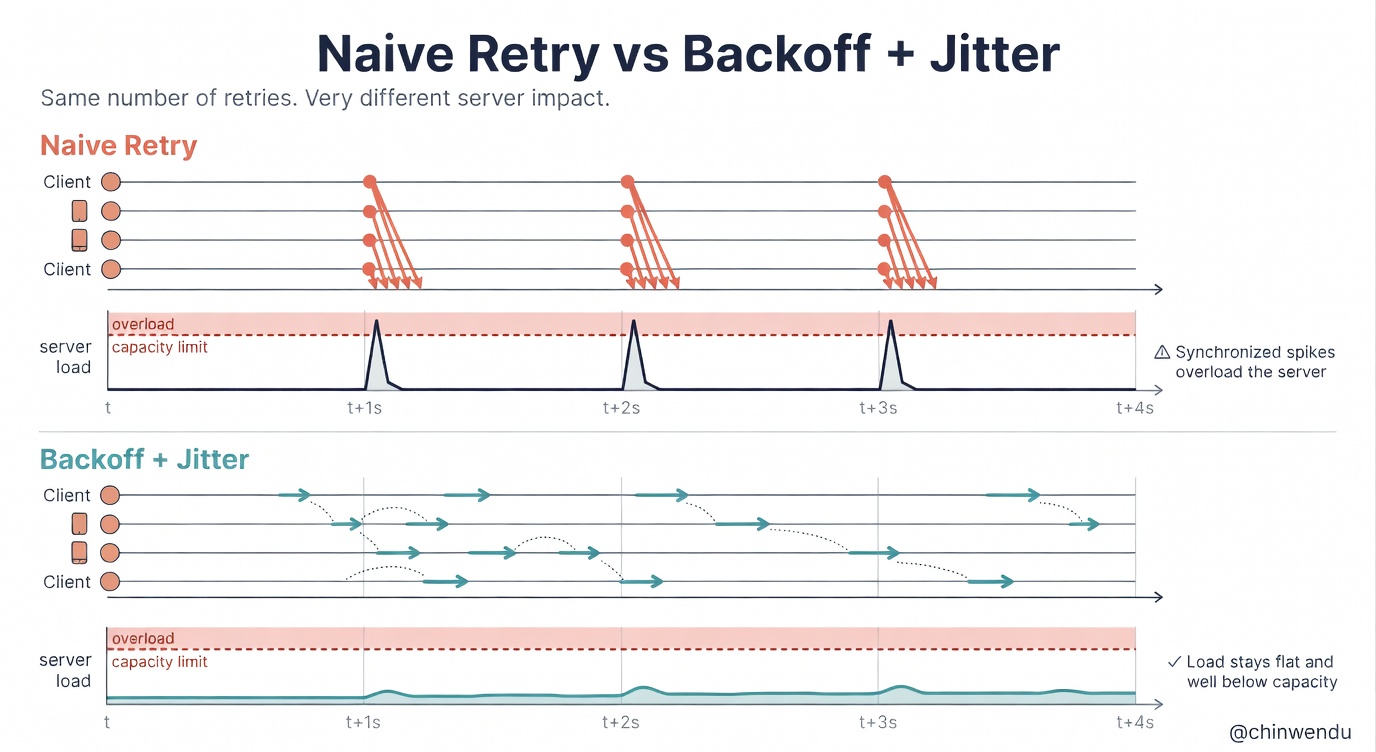
None of these eliminates retries. They shape them.
This pattern is everywhere
Every serious distributed system implements this idea in some form.
AWS SDKs ship with exponential backoff and jitter by default, and their documentation explicitly warns against naive retries. Google’s SRE book formalises retry budgets as a core defence against cascading failure. gRPC has retry policies with configurable backoff. Istio and Envoy let you set retry budgets at the service mesh layer.
None of these systems tries to make retries unlimited. They all constrain retries within a defined boundary.
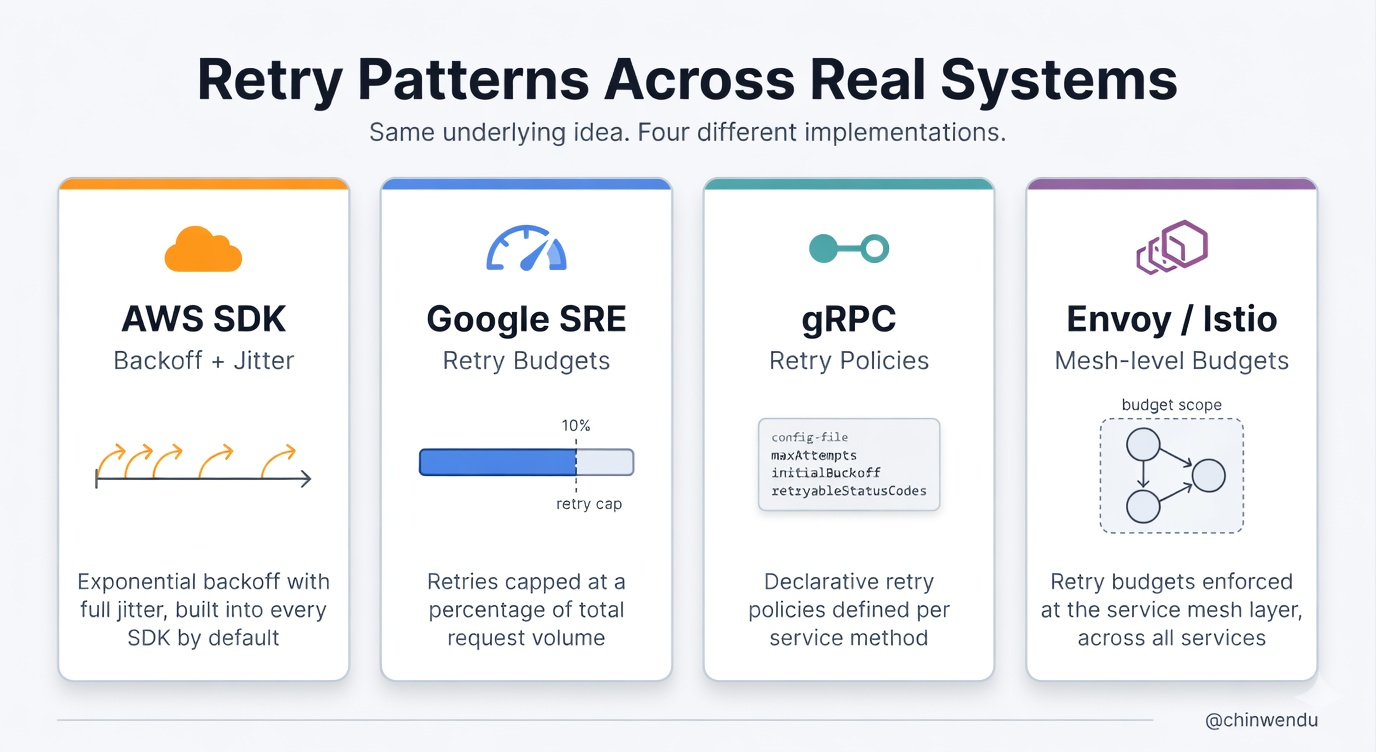
That boundary is what keeps retries from becoming the problem they’re meant to solve.
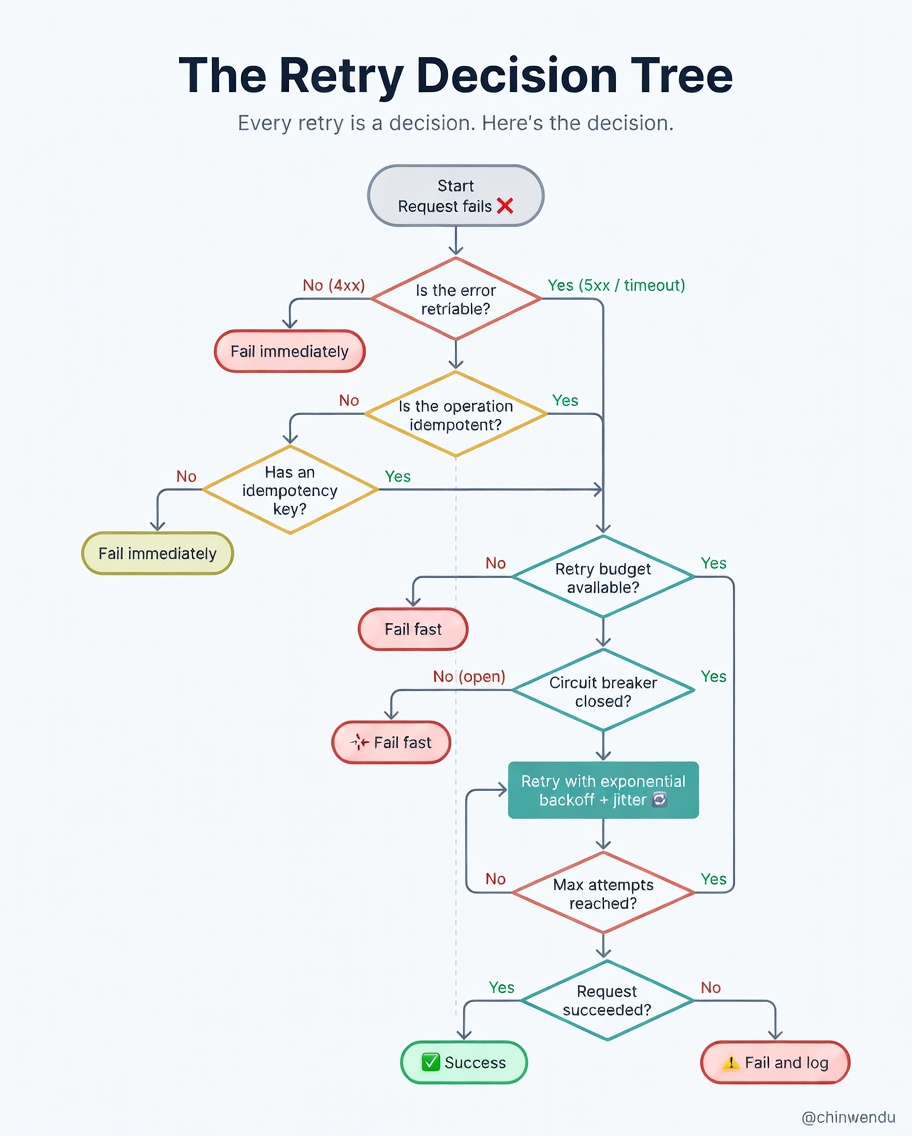
The real decision isn’t whether to retry
It’s what you retry and when you stop.
Not every error is retriable. A 503 or a connection timeout is transient — retry it. A 400 or a 422 means the request is broken; retrying won’t fix it. It’ll just waste resources and potentially worsen a cascading failure.
The same applies to operations with side effects. A GET request is always safe to retry. A POST that charges a card is not — unless you’ve made it idempotent with a client-supplied key.
And critical: every retry needs a stopping condition. Max attempts. A total deadline across all retries combined. A circuit breaker that opens when a downstream is clearly unhealthy, so you stop sending traffic at all for a cooldown window.
You’re not just deciding how to retry. You’re defining your system’s behaviour under stress.
Where things break again
Good retry logic solves the storm problem. It doesn’t solve every problem.
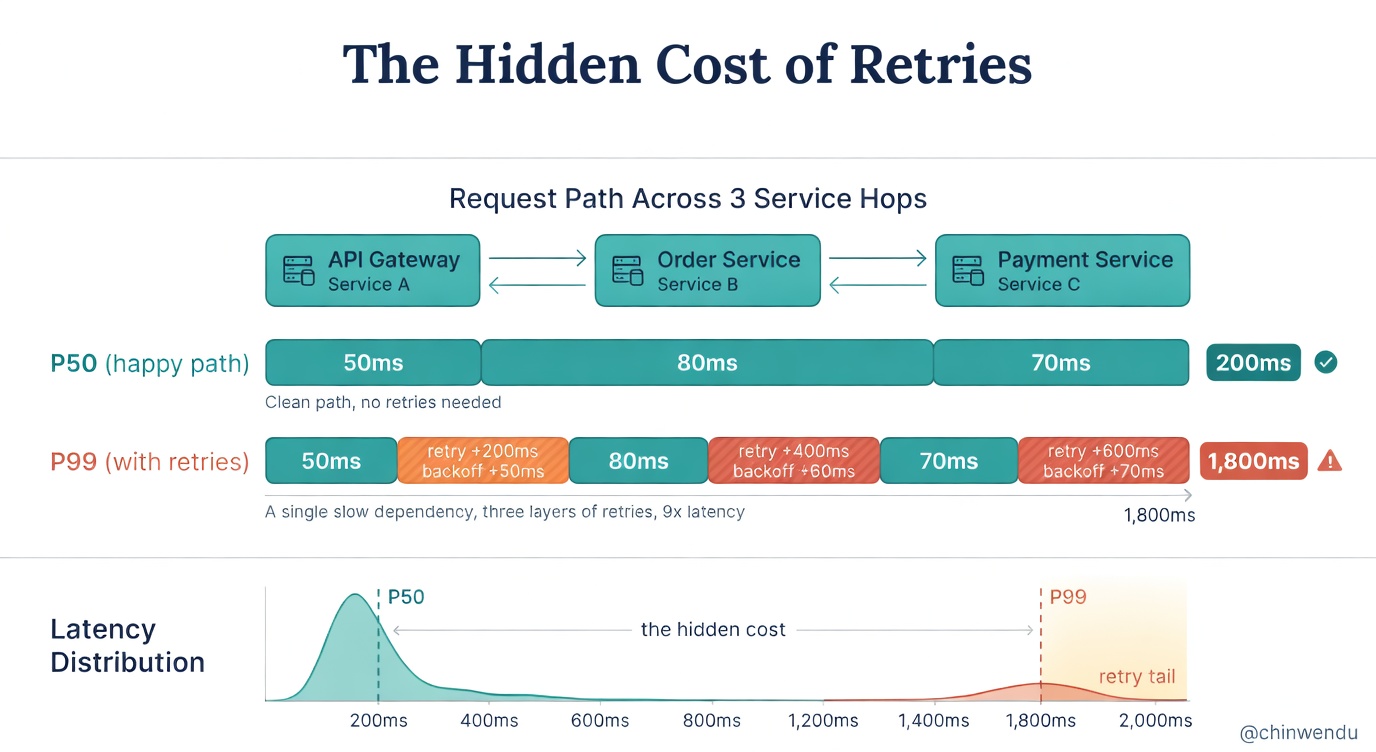
Backoff adds latency. If your P99 is 2 seconds and a retry adds another 2 seconds of backoff plus another 2 seconds of execution, your effective worst case is now 6 seconds or more. Stack that across multiple service hops, and a single slow dependency blows up latency across the entire call chain.
Retry budgets can starve legitimate requests. When the budget is exhausted, new failures don’t get retried at all — even if they would have succeeded. You’ve traded one reliability problem for another.
And idempotency keys are harder than they look. They require storage, TTL management, and careful handling of partially completed operations. Teams often implement them for the happy path and forget the edge cases.
None of this means retries are bad. It means they’re a trade-off, and you should know exactly what you’re trading.
What good retry logic actually buys you
Retry logic doesn’t eliminate failures. It scopes them.
Instead of every transient error becoming a user-facing failure, most of them are absorbed silently. Instead of every downstream hiccup becoming a cascading outage, degradation is contained behind circuit breakers and budgets.
You still have failures. But they’re bounded, observable, and predictable.
That’s what makes distributed systems workable in practice.
Closing Thought
In most backends, retries aren’t designed. They accumulate. A middleware here, a library default there, an SDK setting no one reviewed. It works fine until every layer retries at once and the whole stack folds.
Retries are one of the highest-leverage decisions in your backend. Good retry logic is nearly invisible. Bad retry logic is often invisible until it isn’t.
A better approach is to treat retries as a first-class concern. Decide upfront: what is retriable, how many times, with what backoff, bounded by what budget, and protected by what circuit breaker?
If you don’t design your retry strategy, your outages will.
See you in my next piece. Happy geeking!