If you build with LLMs in 2026, you have probably used all three of these — sometimes in the same system — without being entirely clear on what each one actually is. The terms get mixed up in conversation, treated as competitors, and confused with one another in architecture decisions.
They are not competitors. They solve different problems at different layers of the AI application stack. Mixing them up leads to systems that are over-engineered, under-engineered, or both.
In this article, we will look at what each one actually is, how they fit together, and when to reach for which.
What Each One Actually Is
Before comparing them, it helps to define them precisely. The most common source of confusion is treating all three as the same kind of thing. They are not.
- RAG is a technique. It defines how an LLM gets relevant knowledge at query time.
- Agentic RAG is an architectural pattern. It wraps RAG inside an agent loop that can plan, decide, and iterate.
- MCP is a protocol. It standardises how LLMs connect to external tools and data sources.
A technique, a pattern, and a protocol. Three different categories of things. They can — and often do — coexist in a single system.
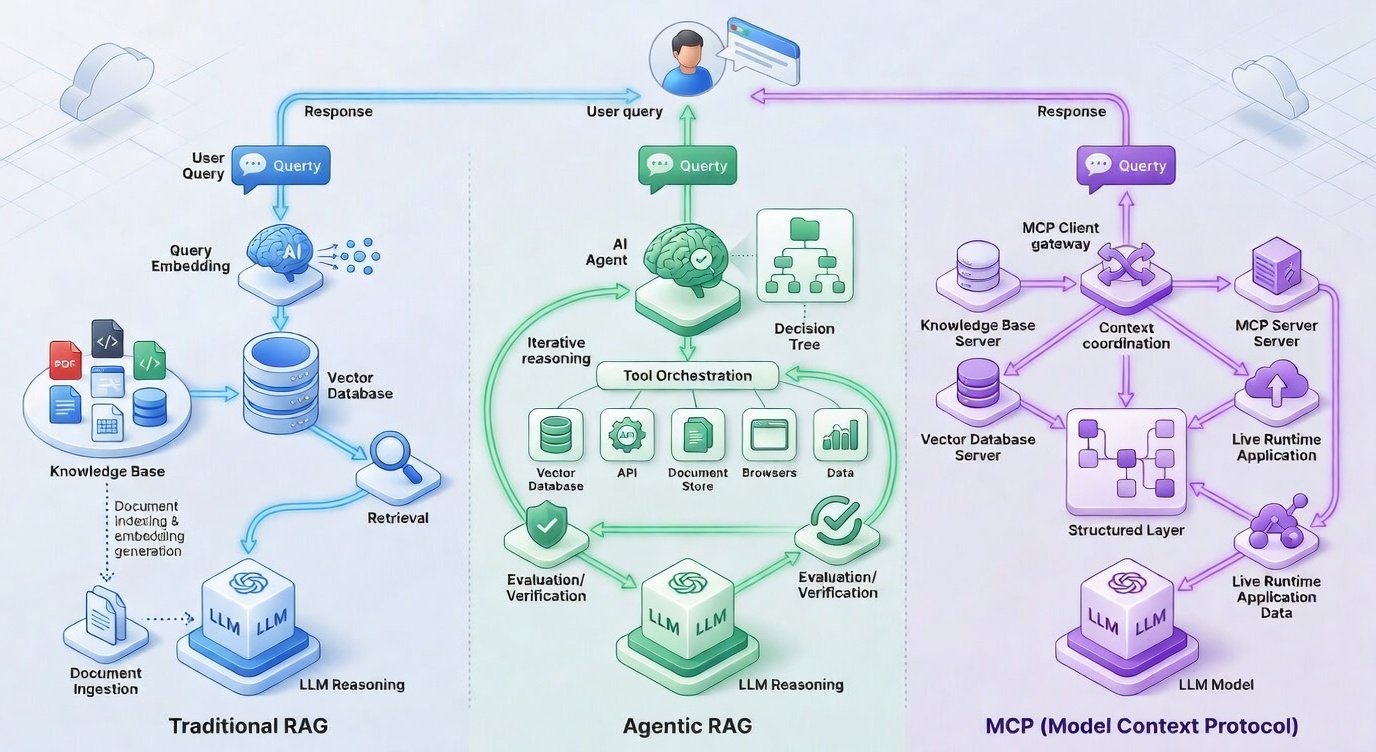
RAG: Retrieval Before Generation
Retrieval-Augmented Generation is the foundational pattern. It solves a specific problem: LLMs have a knowledge cutoff, and their training data does not include your private documents, your live database, or yesterday’s customer support tickets.
The pipeline is straightforward:
- Documents are chunked into smaller passages.
- Each chunk is converted into an embedding (a high-dimensional vector that captures semantic meaning) and stored in a vector database.
- When a user submits a query, the query is also embedded.
- The system performs a similarity search to find the most relevant chunks.
- The retrieved chunks are injected into the prompt alongside the user’s query.
- The LLM generates a response grounded in the retrieved context.
The model never gets retrained. The model never directly accesses your data. It only sees what the retrieval pipeline chooses to show it.
This is the architecture inside almost every “chat with your docs” product, every internal knowledge assistant, and every customer-facing AI that needs to ground answers in specific source material.
What RAG is good at: factual grounding, source citations, reducing hallucinations, and working with frequently updated knowledge bases without retraining the model.
What RAG cannot do: reason about what information it actually needs, refine its own searches, decide between multiple data sources, or take actions on those sources. It is a one-shot pipeline: one query in, one retrieval pass, one answer out.
Agentic RAG: Adding Reasoning to the Loop
Agentic RAG addresses the limitation of traditional RAG, which runs as a single, static pipeline. In real-world queries, one retrieval pass is often not enough. The query may be ambiguous. The first set of retrieved chunks may be irrelevant. The answer may require pulling from multiple sources and combining the results.
Agentic RAG wraps the retrieval step inside an agent loop. The agent itself — an LLM — decides what to retrieve, evaluates whether the retrieved context is sufficient, and re-queries if it is not.
A typical Agentic RAG system contains some combination of:
- Routing agent. Decides which knowledge source to query (vector DB, SQL database, web search, internal API).
- Query planning agent. Breaks complex queries into sub-queries and dispatches them in parallel.
- Tool-use agent. Calls external tools to fetch additional context (calculators, APIs, web search).
- Validation agent. Checks whether the retrieved context actually answers the query, and triggers another retrieval pass if it does not.
The control flow is no longer linear. It is a loop:
plan → route → retrieve → validate → (re-query if needed) → generateA practical example: a user asks an Agentic RAG system, “How did our European customers respond to the Q3 pricing change?” The system might:
- Decompose the query into two sub-queries: “European customer feedback Q3” and “Q3 pricing change details.”
- Route the first sub-query to a vector database of customer support tickets.
- Route the second sub-query to a SQL database of pricing history.
- Validate that both retrieval passes returned sufficient context.
- Synthesise the final answer from both sources.
Traditional RAG cannot do this. It would have made a single similarity search across a knowledge base and returned whatever came back — irrelevant or not.
What Agentic RAG is good at: complex multi-hop queries, querying across multiple data sources, iterative refinement, and handling ambiguous user intent.
What Agentic RAG costs you: latency and money. Each agent step requires an additional LLM call, adding latency overhead. A simple query that took one inference call in traditional RAG might take five or six in an Agentic RAG system.
MCP as a Protocol
MCP — Model Context Protocol — is not an alternative to RAG or Agentic RAG. It is not an architecture for building AI applications. It is a protocol for connecting AI applications to the outside world.
MCP was introduced by Anthropic in November 2024 to solve a specific scaling problem. Before MCP, every integration between an AI application and an external system (Slack, GitHub, a database, a file system) required custom code. If you had M AI applications and N external systems, you potentially needed to build M × N integrations.
MCP turns this into an M + N problem. Tool builders implement an MCP server once for their system. AI application builders implement an MCP client once. Any client can talk to any server.
The architecture follows a familiar client-server model:
- Host. The user-facing AI application (Claude Desktop, Cursor, a custom agent).
- Client. Lives inside the host. Manages the connection to one specific MCP server.
- Server. An external program that exposes capabilities to the AI model in a standardised way.
MCP servers expose three primitives:
- Tools. Functions the LLM can call to take actions (query a database, send a message, write a file).
- Resources. Read-only data sources the LLM can access (files, schemas, documents).
- Prompts. Pre-defined templates for common interactions.
The communication happens over JSON-RPC 2.0, the same lightweight RPC protocol that powers the Language Server Protocol (LSP) in code editors.
The crucial point is that MCP does not decide what the AI does. It only standardises how the AI talks to external systems. An agent decides what to do; MCP provides the wire format for doing it.
How They Combine in Production
In practice, modern AI systems use all three together. The dominant pattern in 2026 is Agentic RAG with MCP-exposed tools.
Here is what the flow looks like:
- The agent layer orchestrates the workflow. It receives the user query, plans a sequence of steps, and decides what to do next at each turn.
- The MCP layer provides standardised access to external systems. When the agent needs to call a tool — query a database, post to Slack, search a file system — it calls it through MCP.
- The RAG layer is one of the tools the agent can use. When the agent needs to ground a response in specific knowledge, it triggers a RAG pipeline (often itself exposed as an MCP server) to retrieve relevant context.
Imagine you’re building an AI assistant for a software team. The flow would look like this:
- A developer asks: “Why did the payment service start failing yesterday at 3 pm?”
- The agent (Agentic) plans the steps: check incident logs, check recent deployments, check related alerts.
- The agent calls a logs MCP server (MCP) to fetch error logs from the payment service.
- The agent calls a deployment MCP server (MCP) to fetch the deployment history.
- The agent triggers a RAG retrieval (RAG) over the team’s runbooks to find related historical incidents.
- The agent synthesises everything into an answer with cited sources.
Three patterns, one system. Each doing what it does best.
Choosing What You Actually Need
Most teams reach for the most complex architecture too early. Ideally, the progression should follow this pattern:
Start with traditional RAG when:
- You have a single knowledge base.
- Queries are mostly direct (one retrieval pass is sufficient).
- Latency matters, and you cannot afford multiple LLM calls per query.
- You are validating whether your retrieval pipeline even works before adding complexity.
Move to Agentic RAG when:
- Queries require multi-step reasoning or pulling from multiple sources.
- Users ask ambiguous or open-ended questions that need clarification.
- Single-pass retrieval has visibly low accuracy (verified through evals, not vibes).
- You are willing to accept higher latency and cost in exchange for higher accuracy.
Add MCP when:
- You are integrating multiple external systems and want to avoid building custom integrations for each.
- You want your AI application to interoperate with other MCP-compatible clients (Claude Desktop, Cursor, IDE plugins).
- You are building a tool ecosystem that other teams or external developers will consume.
Security and Cost Trade-offs Worth Noting
Each pattern comes with its own production concerns.
RAG is the cheapest and lowest-latency of the three, but its accuracy depends entirely on the quality of your retrieval pipeline. Bad chunking, stale embeddings, or a poorly tuned similarity threshold quietly destroy the user experience.
Agentic RAG can cost 3–5× more per query than traditional RAG because each agent step requires its own LLM call. A simple query might take 2–3 steps. A complex one might take 5–10. At scale, this gets expensive.
MCP introduces a security surface that did not exist before. Every MCP tool is an attack surface. Tool inputs need validation. Outputs need sanitisation. Permission scoping matters. The MCP specification addresses some of this with OAuth 2.1 and PKCE, but security researchers have already identified prompt injection vectors via tool responses and attacks based on lookalike tools that silently replace trusted ones. If you expose MCP tools that take destructive actions, you need human-in-the-loop approval for those operations.
These are not reasons to avoid the patterns. They are the reasons to implement them with the same rigour you would apply to any other production system.
Wrapping Up
RAG, Agentic RAG, and MCP are not competing technologies. They sit at different layers of the AI application stack and solve different problems.
- RAG is a retrieval technique. It grounds LLM responses in external knowledge through embed-and-search.
- Agentic RAG is an architectural pattern. It wraps retrieval inside an agent loop that can plan, validate, and iterate.
- MCP is a protocol. It standardises how AI applications connect to external tools and data sources.
The dominant production pattern in 2026 is using all three together: an agent layer for orchestration, MCP for standardised tool access, and RAG (often invoked as a tool through MCP) for knowledge retrieval.
The right question is not which one to use. It is: which combination matches the problem you are actually solving?