
NotebookLM is Google’s AI research tool that answers questions grounded exclusively in your uploaded sources. Unlike general-purpose AI tools that blend training data with your documents, NotebookLM restricts its responses to the content you provide. This design choice, which Google calls source grounding, makes the file upload pipeline architecturally interesting.
When you upload a file, a multi-stage pipeline converts raw bytes into a queryable knowledge base. In this article, we will look at each stage of this pipeline and the infrastructure decisions behind it.
Disclaimer: This post is based on publicly available documentation, API surface analysis, and network inspection. It may differ from the real-world implementation.
The Upload Path
NotebookLM is not a standalone application with a custom backend. It is built on top of Google’s Discovery Engine — the same infrastructure that powers Vertex AI Search. All API calls route through discoveryengine.googleapis.com.
The Enterprise API clearly reveals the upload pattern. Files are sent as raw binary via HTTP POST:
POST https://{LOCATION}-discoveryengine.googleapis.com/upload/v1alpha/
projects/{PROJECT}/locations/{LOCATION}/
notebooks/{NOTEBOOK_ID}/sources:uploadFileThe request includes X-Goog-Upload-Protocol: raw, and a Content-Type header matching the file format. The consumer-facing UI follows the same underlying pattern.
The upload endpoint does minimal work: accept the bytes, write them to a durable queue, and return immediately. Inspecting the network response during an upload reveals this message:
OK: Enqueued blob bytes to spanner queue for processing.This confirms two things: the file is serialised as a binary blob, and it is placed into an asynchronous processing queue backed by Google Cloud Spanner.
Why Spanner as a Queue
Spanner is Google’s globally distributed, strongly consistent relational database. Using it as a queue backend serves three purposes:
Durability. Once Spanner acknowledges the write, the data survives datacenter failures. Spanner uses TrueTime with atomic clocks to maintain consistency across global datacenters. Losing a file after returning “upload successful” is not acceptable.
Transactional dequeue. Workers can atomically claim and process items without duplication. This prevents the common distributed systems bug where two workers process the same file and create duplicate sources.
Metadata co-location. The blob metadata — notebook ID, source ID, upload timestamp, user identity, and processing status — lives alongside the queue entry in a single transactional scope. No separate coordination service is needed.
The 200 OK response received when a file is submitted for upload does not mean the file has been processed. It means Google has accepted responsibility for the file. The heavy processing happens asynchronously downstream. This is the same async-first pattern used by systems like YouTube (accept the upload, transcode later).
The Processing Pipeline
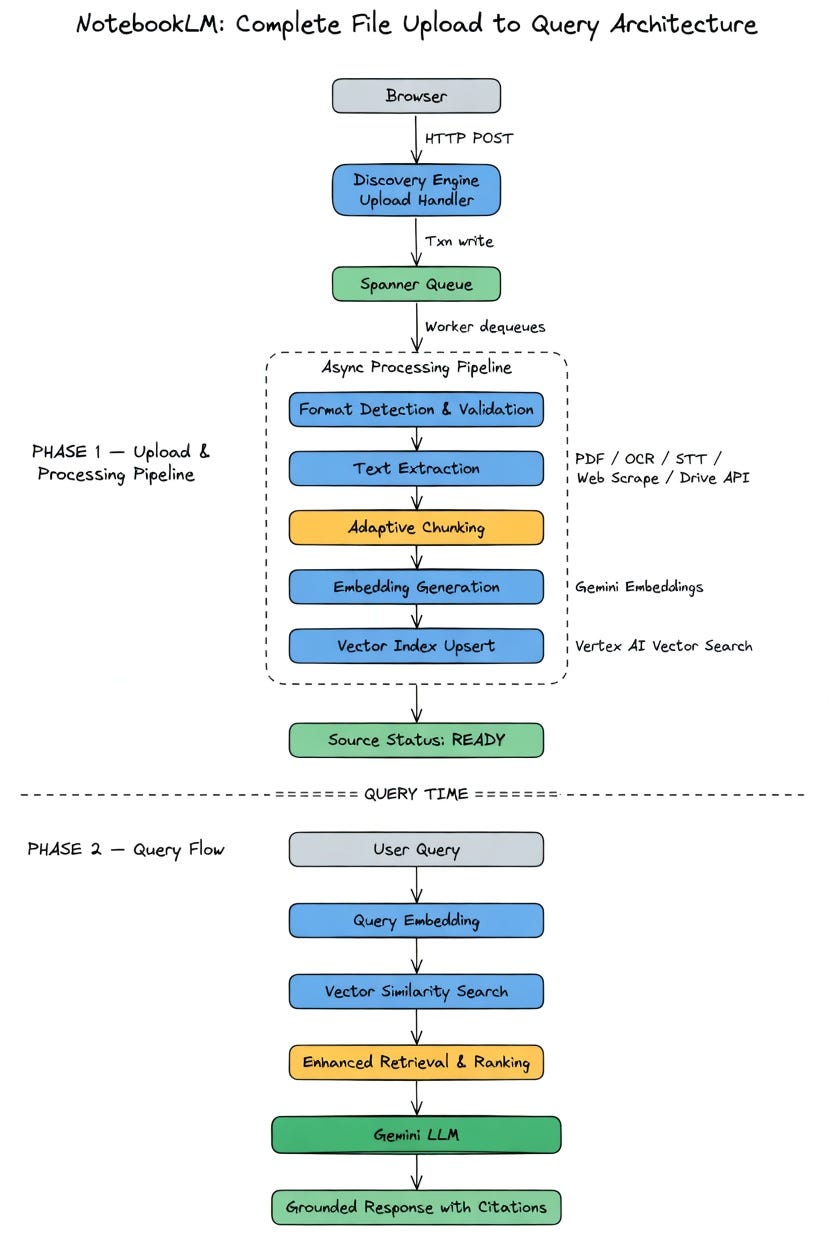
After workers dequeue the blob from Spanner, the file passes through a multi-stage processing pipeline.
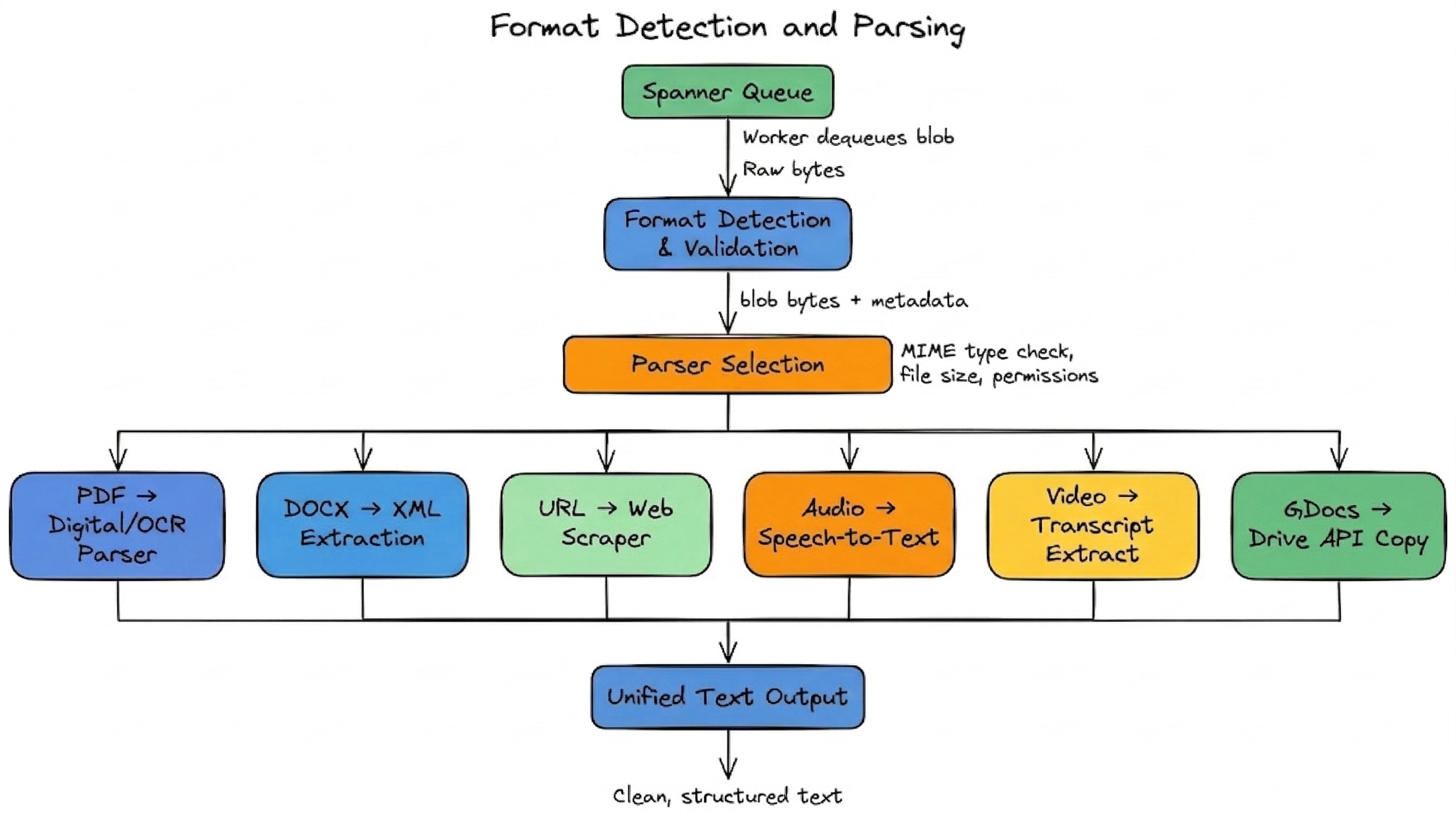
Stage 1: Format Detection and Parsing
The first stage converts diverse file formats into a unified text representation.
NotebookLM supports PDFs, DOCX, TXT, Markdown, CSV, PPTX, Google Docs, Google Slides, Google Sheets, web URLs, YouTube videos, and audio files. Each requires a different parsing strategy:
- PDFs go through a digital parser for standard documents or OCR for scanned content. Google’s Vertex AI Search infrastructure includes layout-aware parsing for complex documents with tables and multi-column layouts.
- Web URLs are fetched and stripped of navigation elements and boilerplate HTML. Only visible text is extracted. Paywalled pages are rejected.
- Audio files are transcribed using speech-to-text services at import time.
- YouTube videos import only the text transcript (user-uploaded or auto-generated captions).
- Google Drive files are copied as a static snapshot. Changes to the original require manual re-sync.
The NotebookLM v1alpha API defines specific failure types that reveal the validation checkpoints in this stage.
If any check fails, the source is marked as failed, and the user sees an error in the UI.
Stage 2: Adaptive Chunking
This is where NotebookLM’s approach diverges from traditional RAG systems.
In a standard RAG pipeline, documents are aggressively chunked into 500–1,000 token segments. These chunks are embedded and stored in a vector database. At query time, the system retrieves the top-K most similar chunks and feeds them to the LLM. This approach has known problems: chunking breaks semantic connections across a document, irrelevant chunks add noise, and maintaining a vector database adds complexity.
NotebookLM uses a hybrid approach. Gemini supports a context window of up to 2 million tokens. For smaller to mid-sized notebooks, entire documents can be loaded directly into the context window without chunking. This preserves the full structural and semantic integrity of the content.
Google’s engineers have been explicit about this distinction. In a recent interview, Steven Johnson, the product lead, called the NotebookLM approach source grounding, distinguishing their approach from traditional RAG. Across dozens of public interviews, the team never discusses standard RAG vocabulary like chunking strategies, vector databases, or top-K retrieval.
The likely architecture is a tiered system:
- Small/medium sources (within context window): Full documents are injected directly into Gemini’s context. No retrieval needed.
- Large sources (exceeding context window): Documents are semantically chunked, embedded, and indexed for retrieval.
This explains a pattern users have noticed: smaller notebooks feel more contextually aware, while very large notebooks occasionally miss connections between distant passages.

Stage 3: Embedding Generation
For sources that go through the retrieval path, the system generates vector embeddings — dense numerical representations of each chunk’s semantic meaning.
Google likely uses their own embedding models (Gemini embeddings or a variant of its text-embedding models). Each chunk is converted into a high-dimensional vector, likely 768 or 3,072 dimensions depending on the model.
These vectors capture meaning, not keywords. For example, two passages about “economic recession” and “financial downturn” produce similar vectors despite sharing no exact words.
Stage 4: Vector Indexing
The embeddings are stored in a vector database with an index optimised for similarity search. The likely backend is Vertex AI Vector Search (formerly Matching Engine).
The index organises vectors for rapid nearest-neighbour search. When a user submits a query, the query is also embedded, and this query vector is compared against the stored chunk vectors to find the most semantically similar passages.
Stage 5: Source Marked as Ready
After all stages are complete, the source status is updated. It transitions from Processing to Ready. The source is now available for querying, summarisation, podcast generation, and all other NotebookLM features.
Query-Time Flow
Once sources are processed, here is what happens when a user asks a question.
Google describes their approach as enhanced retrieval and ranking. The system does not run a single keyword match. Instead, it generates intermediate questions and explores documents from multiple angles before synthesising a response.
The process works as follows:
- Query understanding. The LLM interprets the question, potentially rewriting it to capture different nuances and synonyms.
- Multi-angle retrieval. Multiple phrasings of the query are generated to broaden the search space. This ensures documents using different terminology but aligned semantically are still retrieved.
- Context assembly. Retrieved chunks are assembled into an augmented prompt alongside the original question and system instructions.
- Grounded generation. Gemini processes the augmented prompt and generates a response anchored to retrieved passages. Each claim traces back to a specific passage, enabling inline citations.
The Complete Architecture
Key Architectural Decisions
Several design decisions are worth noting:
Async-first ingestion. Decoupling upload acceptance from processing allows the system to return quickly while handling expensive work (OCR, transcription, embedding) in the background.
Spanner as a coordination backbone. Using Spanner instead of a traditional message broker provides transactional guarantees, global distribution, and metadata co-location in a single system. The blob is likely moved to cheaper object storage after dequeue, with Spanner retaining only metadata.
Hybrid grounding over pure RAG. Leveraging Gemini’s massive context window avoids the information loss from aggressive chunking. Small notebooks use direct injection. Large notebooks fall back on retrieval with sophisticated ranking.
Static copies by design. Snapshotting files at upload time eliminates change detection, incremental re-indexing, and sync conflicts. The tradeoff is manual re-sync when source files change.
Discovery Engine as shared infrastructure. Building on the Discovery Engine rather than a custom backend gives NotebookLM a battle-tested document ingestion and retrieval infrastructure that also powers Vertex AI Search.
Known Constraints
- 50 sources per notebook, each up to 500,000 words or 200MB.
- Static snapshots only. Changes to original files require manual re-sync.
- Text-primary processing with limited support for images within documents.
- Processing delay on large files, especially audio requiring transcription.
- No cross-notebook access — each notebook is an isolated knowledge silo.
Conclusion
NotebookLM’s file upload pipeline converts a raw file into a queryable knowledge source through six stages: blob serialisation, Spanner queue ingestion, format-specific parsing, adaptive chunking, embedding generation, and vector indexing. The architecture prioritises durability (Spanner-backed queue), flexibility (hybrid grounding over pure RAG), and simplicity (static snapshots, shared Discovery Engine infrastructure).
The clear boundary between the synchronous upload and the asynchronous processing pipeline makes source grounding possible.
References
- Google Cloud Discovery Engine API Documentation
- NotebookLM Enterprise API (v1alpha)
- NotebookLM Help Center
- Vertex AI Search — Prepare Data for Ingestion
- Google Engineers Deliberately Avoid Calling NotebookLM “RAG”