One of the first mistakes many engineers (myself included) make when learning backend engineering is searching for the best solution. They ask questions like:
- What’s the best database?
- What’s the best architecture?
- What’s the best way to design this API?
Truthfully, these questions are not inaccurate. After all, most of us learned programming in the same way — by solving problems that had clear, correct answers. A function either works or it doesn’t. A test either passes or fails. And so on. But backend systems don’t work that way.
In backend engineering, there is rarely a single “correct” solution. There are only solutions that fit a specific context. Change the context — traffic patterns, data size, reliability requirements, or cost constraints — and the “best” solution changes with it.
This is why two experienced engineers can disagree, and both be right.
One might choose a simple monolith because the team is small and the product is evolving quickly. Another might choose a distributed design because the system already operates at scale and failures need to be isolated. Neither choice is universally correct. Each is correct for its environment.
The sooner you let go of the idea that backend engineering is about finding perfect answers, the faster you start growing. Backend engineering is not about correctness in isolation; it is about judgment.
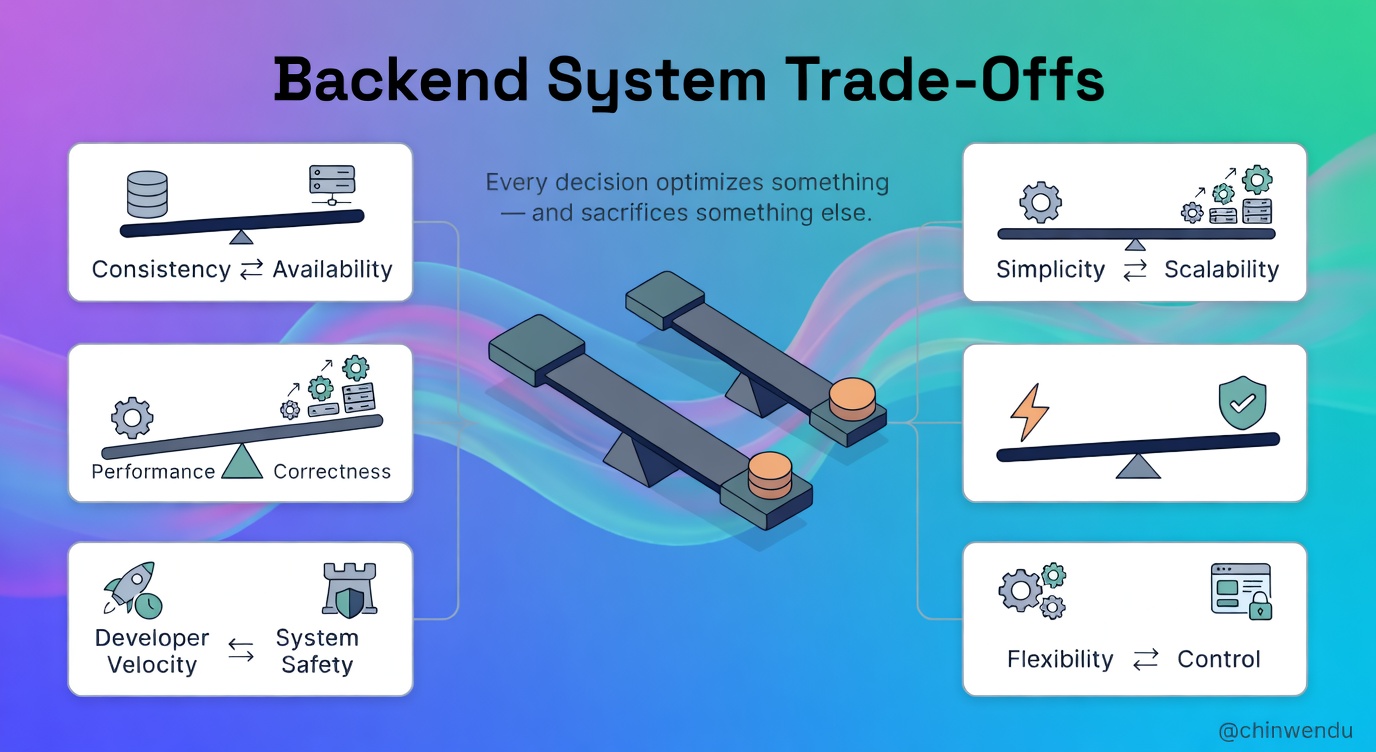
Every Backend Decision Optimises Something
Whether you realise it or not, every backend decision optimises for something.
When you choose a database, you’re optimising for fast reads, strong consistency, flexible schemas, or operational simplicity. Likewise, when you design an API, you’re optimising for ease of use, performance, backward compatibility, or development speed.
The key insight is that you never optimise for everything at the same time. Optimising for performance often increases complexity. Optimising for reliability often increases cost. Optimising for developer velocity often reduces safety.
Even doing nothing is a trade-off. Leaving a system “as is” optimises for short-term stability while sacrificing long-term maintainability.
Many backend problems arise not because engineers made bad decisions, but because they didn’t realise what they were trading away. A system that is fast but inconsistent, flexible but fragile, or simple but unscalable is not broken; it is expressing the priorities with which it was built.
With that said, what questions are better to ask as a backend engineer? An example of a better question would be: What are we optimising for right now, and what are we willing to give up?
Without that clarity, your backend systems can drift — especially as complexity accumulates. Then bugs begin to appear in places no one expects.
Common Trade-Offs in Every Backend System
Trade-Off #1: Consistency vs Availability
One of the most fundamental trade-offs in backend engineering appears the moment your system becomes distributed.
When a system spans multiple servers, data centres, or regions, communication between components can fail. This is typically inevitable in a distributed system. Networks can be slow. Messages can be dropped. Nodes can become unreachable.
When that happens, the system is forced to choose between consistency and availability.
- Consistency, in this context, means that all users see the same, correct data.
- Availability, in this context, means that the system continues to respond to requests even if the data is not the most recent.
You cannot always guarantee both.
If your system prioritises consistency, it may refuse requests when it cannot confirm the latest data. This keeps the data correct, but users may experience errors or downtime.
If your system prioritises availability, it may return slightly outdated or incomplete data so that users can continue working. This keeps the system responsive, but sacrifices accuracy in edge cases.
It is important to note that neither choice is wrong.
A payment system might prioritise consistency (which is ideal in this use case) because showing an incorrect balance is dangerous, can erode trust, and is bad for business. A social media feed might choose availability, because slightly stale data is acceptable if the app stays responsive.
The mistake is pretending this trade-off doesn’t exist.
Many engineers encounter this reality for the first time in production, when systems behave “unexpectedly” under failure. In truth, the system is behaving exactly as designed. The trade-offs just weren’t made explicit.
Understanding this trade-off changes how you design everything downstream: data models, retries, caching, user expectations, and even error messages.
And this is only one example. Backend engineering is filled with these choices. They may appear subtle, but are unavoidable and deeply impactful.
Trade-Off #2: Simplicity vs Scalability
Simple systems are easy to understand. However, scalable systems are rarely simple.
Early in a product’s life, simplicity is usually the right choice. A single service, a single database, and straightforward data flows that allow teams to move quickly. Bugs are easier to reason about. New engineers get onboarded faster. Changes are cheaper.
But simplicity has limits. As traffic grows, data volume increases, and reliability requirements become stricter, the assumptions that initially made the system simple begin to break down. One database becomes a bottleneck. One service becomes overloaded. A single failure affects everything.
Scalability introduces techniques that intentionally add complexity. They include techniques such as sharding, replication, background processing, caching layers, message queues, and service boundaries. Each of these solves a real problem, and each makes the system harder to reason about.
Now, this is where many teams go wrong. Some design for scale far too early, adding complexity they don’t yet need. Others cling to simplicity long after it has stopped serving them. As a result, patching problems instead of addressing root causes.
This trade-off is unavoidable. You are either paying complexity costs now or paying operational pain later.
Good backend engineering is not about always choosing scalability. It is about recognising when simplicity becomes a liability and deliberately evolving the system rather than reacting.
Trade-Off #3: Performance vs Correctness
Performance is visible. Correctness is often invisible, until it isn’t.
A fast system that occasionally returns incorrect data may feel fine during development and testing. But under real load, those inaccuracies surface as missing updates, duplicate actions, or an inconsistent state that’s hard to reproduce.
Correct systems tend to be slower because correctness requires coordination. Transactions need locks. Distributed systems need consensus. Validation takes time.
Every shortcut taken for speed risks introducing subtle errors such as skipping validation, weakening consistency guarantees, or assuming requests won’t overlap.
On the other hand, systems that prioritise correctness at all costs can become slow, brittle, and expensive to operate. Users experience delays. Engineers fight performance bottlenecks. Infrastructure costs climb.
In this scenario, the key question is not “should this be fast or correct?” but: What happens if this is wrong?
For a payment system, correctness is non-negotiable. For an analytics dashboard, slight delays or approximations may be acceptable.
Backend engineers who understand this trade-off design systems that are fast where they can be, and correct where they must be. This distinction is rarely obvious in code, but it defines system reliability over time.
Trade-Off #4: Developer Velocity vs System Safety
Moving fast feels good until it doesn’t. High developer velocity allows teams to ship features quickly, experiment freely, and respond to user feedback.
But speed often comes at the cost of safeguards: fewer in-depth reviews, rushed testing, and risky deployments.
System safety slows things down. It introduces friction: code reviews, automated tests, staging environments, gradual rollouts, feature flags, and observability. None of these directly adds features, but all of them reduce risk.
This trade-off becomes painful when systems grow.
In small systems, mistakes are cheap. But in large systems, mistakes propagate downstream. A small change can affect thousands of users, corrupt data, or trigger cascading failures.
Teams that prioritise velocity without safety eventually slow themselves down. Every deployment becomes stressful. Rollbacks are common. Engineers hesitate to make changes because the system feels fragile.
Mature backend teams aim for sustainable velocity, that is, moving fast without breaking trust. They invest in guardrails not because they are cautious, but because they understand the cost of failure.
Speed without safety is not velocity. It is debt with interest.
Trade-Off #5: Flexibility vs Control
Flexible systems feel empowering. They allow dynamic configurations, loosely defined schemas, optional fields, and highly customisable behaviour. Teams can move quickly because the system doesn’t push back. Almost anything is allowed.
But flexibility has a cost. As a system grows, flexibility often turns into ambiguity. Different parts of the system begin to interpret data differently. Assumptions drift. Edge cases multiply. Debugging becomes harder because behaviour depends on configuration, context, or historical data rather than explicit rules.
Control introduces constraints: schemas, contracts, validation rules, and strict interfaces. These guardrails limit what developers can do, but they also make systems predictable.
This trade-off is subtle but important. Flexible systems optimise for short-term adaptability. Controlled systems optimise for long-term stability.
Backend engineers who ignore this trade-off often end up with systems that are technically powerful but operationally fragile. Engineers who understand it apply flexibility intentionally, while enforcing control at boundaries where correctness and clarity matter most.
Why Trade-Offs Get Harder in Production
Many backend trade-offs seem theoretical until a system reaches production.
In development, traffic is predictable. Failures are rare. Data volumes are small. Assumptions feel safe. But production changes everything.
Load exposes bottlenecks that never appeared in testing. Rare edge cases occur regularly. Network failures stop being hypothetical. Latency becomes visible. All these small inefficiencies compound into real costs.
This is why backend systems often behave “fine” until they don’t. Trade-offs that felt harmless earlier become painful at scale: retries overwhelm downstream services, caches serve stale data, background jobs pile up, and databases become hotspots.
Production doesn’t introduce new problems. It only amplifies existing ones. And backend engineers who understand these design systems with failure in mind. They expect partial outages. They assume dependencies will misbehave. They accept that some decisions will need to be revisited as the system evolves.
This mindset doesn’t eliminate trade-offs. It makes them survivable.
How Senior Backend Engineers Think About Trade-Offs
I asked a few senior engineers I know about this, and they shared a few tips with me. Senior backend engineers don’t magically make better decisions. They’ve learned to ask better questions.
Instead of asking: Is this fast? They ask: What happens when this slows down? Instead of asking: Does this scale? They ask: What breaks first when traffic increases?
They think in terms of blast radius, failure modes, and long-term maintenance. They choose boring, proven solutions because they understand the cost of novelty. They write things down. They make trade-offs explicit. They accept imperfection as part of engineering.
Most importantly, they understand that backend engineering is not about eliminating trade-offs, but owning them.
What am I Driving At?
There is no perfect backend system.
Every backend system is a collection of compromises. Some are made consciously, while others are inherited. Many are discovered only after something breaks.
The difference between fragile and resilient systems lies not in the absence of trade-offs, but in the presence of intentionality. Backend systems built with intentionality reflect clear priorities: what must be correct, what can be eventually consistent, what should be simple, and what can afford complexity.
Backend engineering is the practice of making these choices repeatedly, under changing constraints, with incomplete information.
There is no perfect backend architecture. There are only systems that match their context, and systems that don’t.
Learning backend engineering is not about memorising tools or patterns. It is about understanding the trade-offs, making decisions deliberately, and accepting the consequences responsibly.
Once you see backend engineering this way, frameworks matter less, tools change more easily, and your judgment improves faster than your syntax ever could.